讲透数据血缘!建议收藏
你们公司大概率发生过这两种"事故"。
第一种:一个字段改名/口径调整,第二天一堆报表一起炸,业务群里一句话——"数据中心又把我 KPI 搞没了"。
第二种:监管/审计问一句——"这个指标从哪来?经过哪些加工?谁批准的?",全场沉默,然后开始人肉翻 SQL、翻作业、翻脚本、翻 Excel。
数据血缘,本质上就是为了解决这两类问题:变更影响可控,以及追责与解释可证。
但血缘之所以难落地,是因为很多人把它当成"画图工程"。画出来一张巨大的蜘蛛网,挂在平台里,很酷,然后没人用。
真正能落地的血缘,是一套"可追溯、可裁决、可控制"的系统能力。
下面我用一篇文章,把数据血缘讲透:讲清楚它是什么、不是什么;为什么做、做到什么程度才值;怎么做才不会变成摆设;以及一条适合大多数企业的落地路线。
第0章:先做一个"3问测试"——你们到底有没有在"裸奔"?在深入探讨之前,请先回答下面三个问题:
问题1:改一个字段,你知道会影响谁吗?比如把 user_id 从 INT 改成 STRING,或者把 gmv 的计算口径从"含税"改成"不含税"。
答案普遍是:不知道。
要么靠人肉问一圈"谁在用这张表",要么直接改了再说——出事了再修。
问题2:报表数字异常,你能在30分钟内定位到哪一步出问题吗?指标跌了50%,是源头数据晚到?是 ETL 逻辑被人改了?是维表更新了?还是 BI 口径被人动了?
答案:不知道。
没有运行血缘,你只能靠人肉排查——翻代码、翻日志、翻调度记录,运气好半天,运气不好一周。
问题3:审计问你"这个指标怎么来的",你能在1小时内给出证据链吗?监管/审计/内控关心的是:来源是否合规、加工是否可控、链路是否可追责。
答案:不能。
大多数企业的血缘是"理论链路",不是"证据链"——你能画出从 A 到 B 的箭头,但你拿不出"这次跑批到底读了什么、产出了什么、谁批准的"。
如果这三个问题你一个都答不上来,那么恭喜你——你的企业正在"裸奔"。
数据血缘时代的第一原则很简单:
如果你不知道数据从哪来、到哪去、谁负责,你就不可能控制数据。
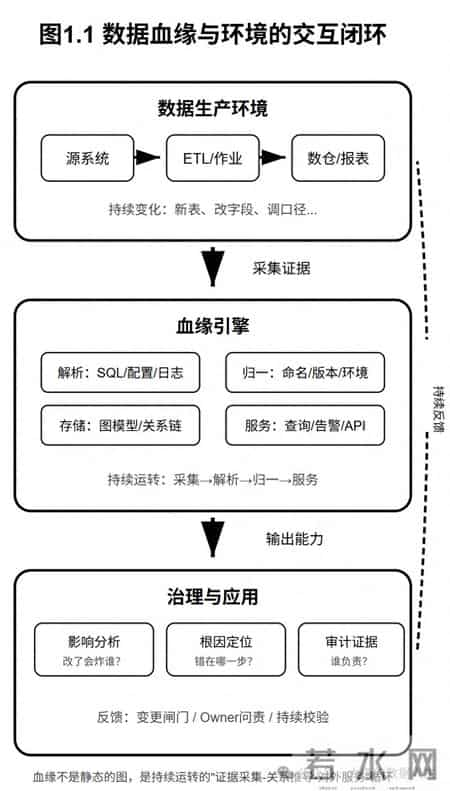
第一章:初识数据血缘欢迎来到数据血缘的世界!在数据驱动决策的今天,数据血缘已成为企业数据治理的"中枢神经"。无论你是数据治理负责人、数据工程师,还是希望深刻理解数据架构的观察者,掌握数据血缘的本质,都将是你知识体系中不可或缺的一环。
1.1 什么是数据血缘?在探索任何一个复杂概念时,我们最好从一个简洁的定义开始。
数据血缘(Data Lineage)是指对数据对象之间"来源 → 加工 → 去向"的可追溯关系进行系统性记录与管理的能力。
但这个定义太空。要讲透,必须把血缘拆成三个要素:
数据对象(Object):血缘追踪的主体是什么?表、字段、指标、报表、接口、文件……所有承载数据的载体。
变换逻辑(Transformation):数据怎么从 A 变成 B?SQL、ETL 作业、脚本、规则引擎、人工加工……所有改变数据的操作。
证据链(Evidence):你凭什么说"A 经过 T 变成了 B"?元数据、运行日志、版本快照、审批记录……所有可以"自证清白"的材料。
真正的数据血缘,是对象 + 变换 + 证据的闭环。
如果把企业的数据架构比作城市的交通网络,数据血缘就是一张实时的、动态的交通流向图。它主要回答两个核心问题:
 1.2 数据血缘不是什么
1.2 数据血缘不是什么
为了让你更清晰地理解数据血缘的边界,我们需要明确区分几个容易混淆的概念:
误解 1:血缘就是"元数据管理"的一个图
不对。元数据是"名录",血缘是"因果链"。名录告诉你"有什么",因果链告诉你"为什么会这样、改了会怎样"。
误解 2:血缘做得越全越好
不对。血缘是成本极高的能力,尤其到字段级、逻辑级、运行级。血缘不是"全域建模",而是"围绕高价值场景逐步加深"。
误解 3:买个平台就有血缘
不对。血缘的数据来源来自你的数据生产链路:ETL/ELT、调度、SQL、流式任务、BI 语义层、接口同步、脚本、甚至人工 Excel。平台只是容器,不是血缘本身。
误解 4:全自动字段级解析就算成功
不对。静态解析只能覆盖"写死的 SQL",动态 SQL、UDF、存储过程、宏变量——这些才是企业的"主战场",而它们恰恰是静态解析的盲区。
1.3 血缘和这些概念的边界这里给一张"概念对照表",非常适合收藏:
 1.4 一个类比:文件的"户籍系统"
1.4 一个类比:文件的"户籍系统"
我们可以用一个类比来理解完整的数据血缘体系:
想象每一个数据对象都是一个"公民",那么:
没有户籍系统,边检就是一团乱麻;没有血缘系统,变更管理就是盲人摸象。
本章小结用 5 句话把"血缘的正确姿势"收束:
- 血缘是因果链,不是关系图——它要回答"为什么会这样、改了会怎样"。
- 血缘的最小单元是:对象 + 变换 + 证据——三者缺一不可。
- 血缘不是越细越好——"表级跑通 + 关键指标字段级"通常性价比最高。
- 血缘不是买个工具就有——它来自你的数据生产链路,工具只是容器。
- 血缘的终点不是"看见",而是"控制"——能进流程、能问责、能审计。
上一章,我们明确了数据血缘的定义与边界。但在实际落地时,一个绕不开的问题是:血缘要做到什么程度?
这个问题的答案,决定了投入成本与实际收益。本章将从三个维度对数据血缘进行分类,帮你建立"立刻清晰"的认知框架。
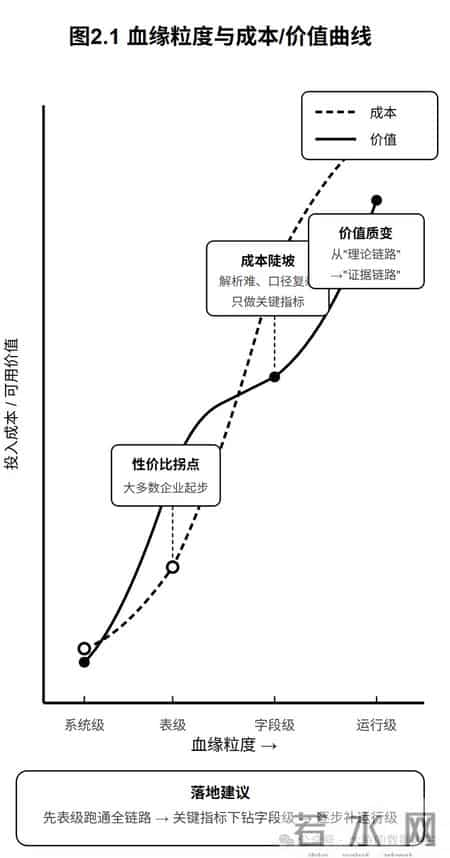
2.1 按粒度分:系统级 / 表级 / 字段级 / 运行级数据血缘的粒度,决定了它能回答什么问题、解决什么场景、付出什么代价。

关键洞察:运行级血缘才是真正"救命"的血缘。
为什么?因为前三种都是"理论血缘"——告诉你"应该怎么流";只有运行级血缘才是"证据血缘"——告诉你"这次到底怎么流的"。
当指标异常时,你需要知道的不是"理论上 A 应该流到 B",而是"这次跑批,A 的哪个分区流到了 B 的哪个分区,中间哪一步失败了"。
 2.2 按"血缘视角"分:概念血缘 / 技术血缘 / 运行血缘
2.2 按"血缘视角"分:概念血缘 / 技术血缘 / 运行血缘
从使用者的视角,血缘可以分为三层:
概念血缘(Business Lineage)
技术血缘(Technical Lineage)
运行血缘(Operational Lineage)
90% 的企业只做了技术血缘的一部分,然后希望它解决全部问题——这就是落地失败的根因之一。
2.3 按采集方式分:静态血缘 / 动态血缘 / 混合血缘血缘数据从哪来?主要有两种采集路径:
静态血缘(Static Lineage)
动态血缘(Dynamic Lineage)
混合血缘(Hybrid Lineage)
现实中,静态 + 动态结合是最可行的方案:
根据行业实践,大多数企业的血缘实施效果是这样的:
指标
厂商 PPT
技术采集
实际可用
覆盖率
80%+
40%-60%
20%-30%
为什么差距这么大?
- 技术采集有大量遗漏(代码逻辑、动态 SQL、非标准数据源)
- 采集到的血缘缺乏业务语义,无法支撑决策
- 血缘信息过时,与实际不符
- 血缘粒度不够,无法满足实际需求
给读者一个结论:别一上来就字段级,把钱烧在"可用性"上。
- 表级血缘是性价比拐点——大多数企业从这档起步最划算
- 字段级血缘是成本陡坡——只做关键指标链路,逐步扩展
- 运行级血缘是价值质变——从"理论链路"变成"证据链路"
- 静态 + 动态混合是现实最可行的方案
- 接受永远无法 100% 覆盖的现实——关键是覆盖最重要的资产
在明确了血缘的分类与粒度后,本章将探讨一个核心问题:血缘系统是怎么跑起来的?
如果说上一章讲的是"血缘长什么样",这一章讲的就是"血缘怎么来的"。
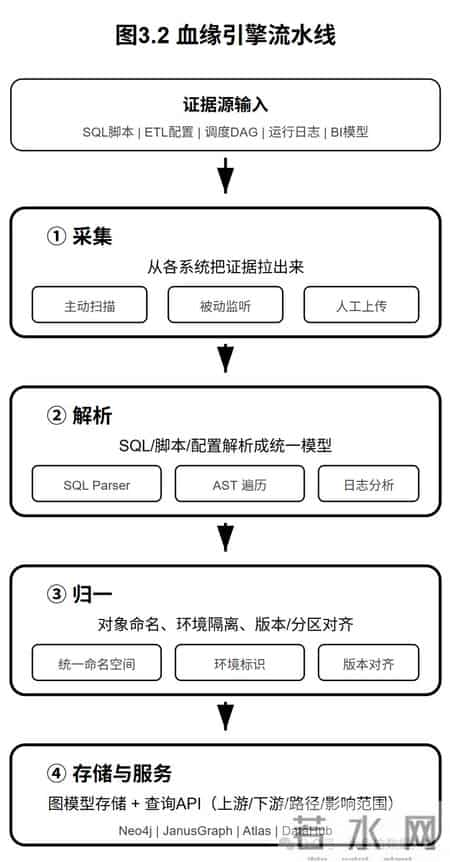
3.1 血缘的"证据源"从哪来血缘不是凭空生成的,它来自可解析、可采集的证据。常见来源有六类:

一句话:血缘落地,本质是把这些证据源"接起来",并且让它持续更新。
3.2 血缘引擎的四件事一个完整的血缘引擎,需要做四件事:
 3.3 血缘的核心"循环":变更—影响—验证—回写
3.3 血缘的核心"循环":变更—影响—验证—回写
血缘要成为控制系统,必须进入一个持续运转的循环:
① 变更发生
字段改名、作业逻辑调整、口径变更、源头切换……数据生产环境每天都在变。
② 自动计算影响范围
血缘系统实时检测变更,自动计算:这个变更会影响哪些下游报表、指标、接口?
③ 验证与发布
高风险变更触发审批流程;灰度发布、对账验证、回滚点准备。
④ 回写血缘快照与责任记录
变更完成后,血缘系统记录:谁改的、改了什么、影响了什么、验证结果是什么。这是审计与追责的"证据链"。
关键洞察:血缘要成为控制系统,必须进入这个循环,而不是停在可视化。
3.4 血缘的正确使用方式血缘要能用,至少要具备三种使用方式:
① 查询式血缘
给我一个对象(表/字段/指标/报表),返回:上游、下游、路径、影响范围、Owner、最近变更、运行状态。
② 差异式血缘
同一个对象,两次发布/两次运行,血缘发生了什么变化?这是"变更管理"的核心。
③ 事件式血缘
当某个上游数据延迟/异常/口径变更,自动标记可能受影响的下游对象,并通知对应 Owner。这一步,血缘才真正进入"控制系统"。
可视化只是结果,不是目标。如果你们只追求一张图,最后一定没人用。
本章小结用一句话收束:血缘的本质是"证据链",证据链的本质是"可重复证明"。
- 证据源决定成败——抓不住证据源,血缘永远停留在"看起来像"
- 血缘引擎四步走——采集→解析→归一→存储服务
- 血缘必须进入"变更—影响—验证—回写"循环——否则就是摆设
- 三种使用方式——查询式、差异式、事件式,缺一不可
理论知识固然重要,但最好的学习方式是亲手实践。在本章中,我们将引导你快速构建一个"最小可用"的血缘能力。这个过程将让你直观地感受到:血缘不是高不可攀的平台工程,而是可以从小处起步的实用能力。
4.1 目标:做到两件事就算成功在开始之前,先明确目标。一个"可用"的血缘 MVP,需要支撑两个核心动作:
动作 A:给定一张表,查出上游和下游
"ads_gmv 这张表,上游依赖哪些表?下游被哪些报表引用?"
动作 B:给定一次变更,列出受影响的报表/指标清单
"如果我要改 dwd_order.pay_amt 这个字段,哪些下游报表会受影响?"
只要这两件事能稳定发生,血缘就开始"值钱"了。
4.2 最小实现路径根据你的技术栈,这里给三条可选路线:
 4.3 你必须告诉读者的现实边界
4.3 你必须告诉读者的现实边界
在动手之前,必须先接受几个现实:
边界 1:动态 SQL / UDF / 宏变量会让字段级不可靠
静态解析器遇到 EXEC('SELECT * FROM '+@tableName) 这种动态拼接,基本无能为力。所以字段级血缘的准确率,不要追求 100%。
边界 2:人工 Excel / 临时报表是"血缘黑洞"
业务自己拉了一份数据到 Excel,加工后发给领导——这条链路,技术手段采集不到。这部分要靠流程管控和文化建设。
边界 3:所以要有"置信度"和"人工校正入口"
好的血缘系统,会给每条血缘关系标注"置信度"(高/中/低),并提供人工校正的入口。机器自动处理 80%,人工审核 20%,这才是可持续的模式。
4.4 一个真实的 MVP 案例假设你用 dbt 管理数仓,5 分钟跑通血缘的步骤:
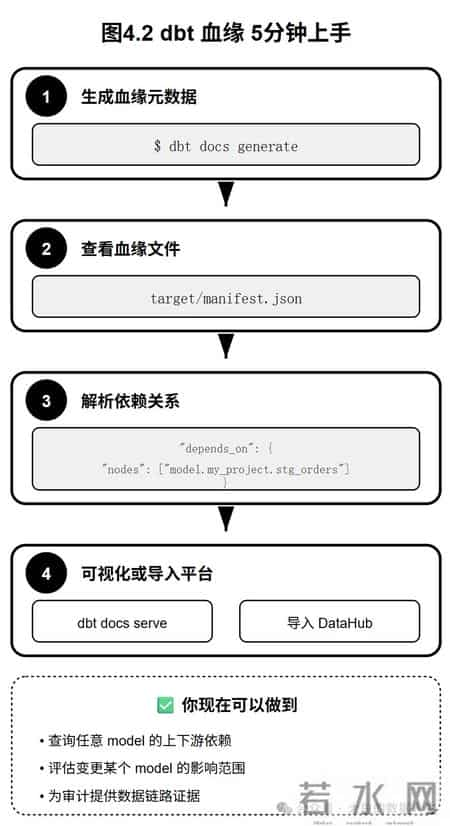 本章小结
本章小结
强调"先跑通 MVP,再扩覆盖面",别一口吃胖子。
- 目标要明确——做到"查上下游 + 算影响范围"就算成功
- 路径要选对——根据技术栈选择 dbt / OpenLineage / BI 语义层
- 边界要接受——动态 SQL、Excel 黑洞、准确率不可能 100%
- 模式要正确——机器 80% + 人工 20% = 可持续的治理闭环
在前面的章节,我们从概念到实践,逐步建立了对数据血缘的完整认知。但血缘的真正价值,不在于技术实现的精妙,而在于它能否成为企业的"组织武器"。
本章将探讨血缘的两种核心协作模式:作为工程效率工具,以及作为治理控制点。
5.1 作为"工程与排障工具"这是一线数据人最直接感受到的价值。
场景 1:影响分析——上线前先算"会炸谁"
数据工程师计划重构底层宽表,或者修改某个字段的类型。
过去:靠人肉问一圈"谁在用这张表",或者直接改了再说,出事了再修。
有血缘:一键查出所有下游依赖,提前通知相关人员,变更前评估风险。
场景 2:根因定位——指标异常沿链路回溯
CEO 发现驾驶舱里的"营收数据"异常下跌,数据团队需要紧急排查。
过去:翻代码、翻日志、翻调度记录,运气好半天,运气不好一周。
有血缘:一键回溯指标的上游链路,快速定位是哪一步出问题——源头延迟?ETL 逻辑改了?维表更新了?
场景 3:复用与降本——识别重复加工、僵尸链路
数据平台存储成本居高不下,但没人知道哪些表是"没人用的"。
过去:不敢轻易下线,怕误伤。
有血缘:通过血缘分析,识别出没有任何下游依赖的"孤岛数据",安全下线,节省成本。
5.2 作为"治理控制点"这是管理层最愿意投钱的理由——因为它能"控风险"。
控制点 1:变更闸门——未做影响分析不准改
建表、改字段、改口径、上线接口、改作业逻辑,都必须触发影响分析与审批。
不进流程的变更,不准上线。这是血缘从"可视化"变成"控制系统"的关键一步。
控制点 2:审计证据——谁改的、改了什么、影响了什么、怎么验证的
当监管/审计问"这个指标怎么来的",你能在 1 小时内给出:
这不是"最好有",这是"必须有"。
控制点 3:Owner 制度——对象责任人、链路责任人、审批责任人
血缘图上每个关键对象必须有 Owner:
没有 Owner,血缘就是一张没人认领的图。
5.3 "文档式治理" vs "血缘式治理"这是两种截然不同的治理范式:
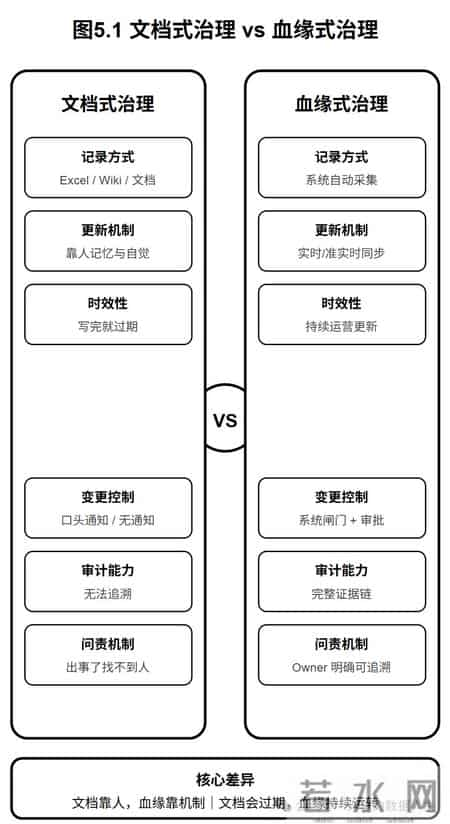
核心差异:文档式治理靠人的记忆与自觉,血缘式治理靠系统的机制与证据链。
一个会过期,一个会自动更新。
一个出事了找不到人,一个能追溯到每一步的责任人。
本章小结血缘的价值不在"看见",在"让组织能控制变化"。
- 作为工程工具——影响分析、根因定位、复用降本
- 作为治理控制点——变更闸门、审计证据、Owner 问责
- 从文档式治理升级到血缘式治理——靠机制而不是靠人
数据血缘项目的失败率高达 80%。不是技术不行,而是"没想清楚就下手"。
本章给管理者一套决策清单,帮你判断:该不该做、怎么做、怎么验收、怎么避坑。
6.1 立项前的 3 个判断问题在决定投入之前,先回答三个问题:
问题 1:你们一年有多少次"变更引发事故"?
如果答案是"很多,但说不清具体多少"——恭喜你,这本身就是问题。
变更引发的事故,是血缘最直接的止血场景。如果一年下来,因为字段改名、口径调整、上游延迟导致的报表问题超过 10 次,血缘就值得做。
问题 2:指标异常平均定位要多久?靠谁?
如果定位一个指标异常需要 2 小时以上,或者完全依赖"那个老员工"——说明你们没有可追溯的链路。
血缘能把定位时间从"小时级"压缩到"分钟级",把知识从"人脑"迁移到"系统"。
问题 3:审计/监管能否在 1 小时内拿出证据链?
如果答案是"不能"或者"需要几天"——你们在合规上有风险敞口。
血缘是审计证据的核心来源。没有它,你只能人肉翻代码、翻文档、翻邮件。
如果三个问题你都答不上来,先别急着做血缘——先把痛点量化出来。
6.2 落地路线图:三期推进 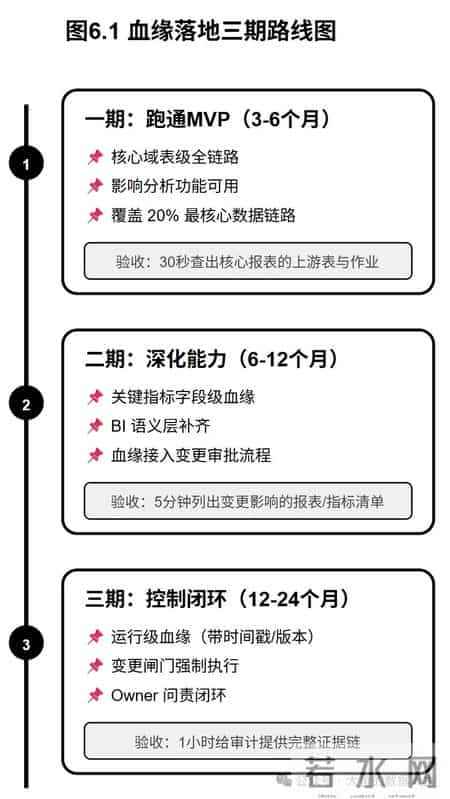 6.3 验收标准:用可量化指标说话
6.3 验收标准:用可量化指标说话
不要看"图画得多大",看这 6 条能不能做到:
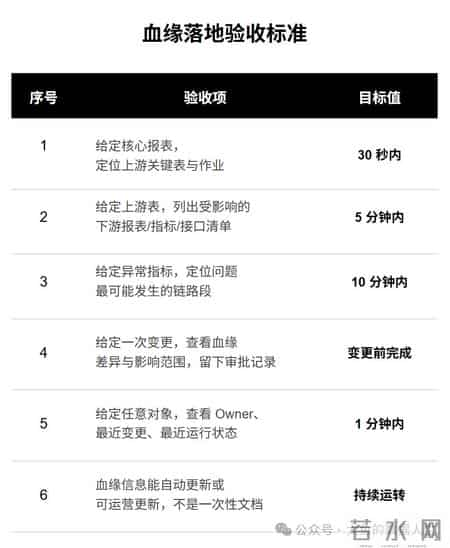
满足其中 4 条以上,这个血缘就已经开始"值钱"。
6.4 最常见的 9 个坑 + 对应解法 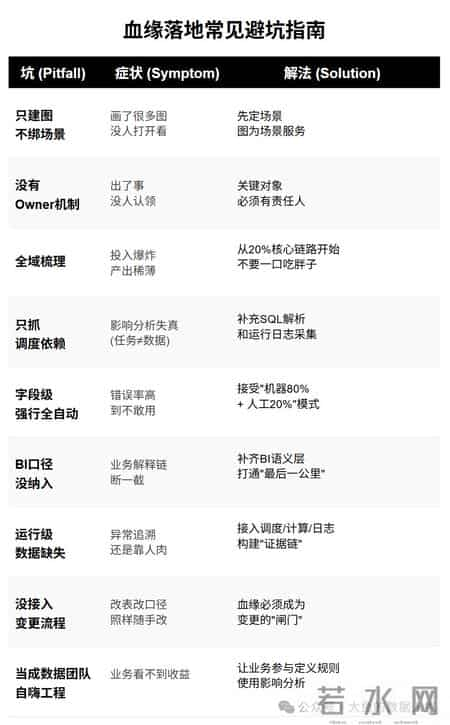 本章小结
本章小结
一句话结尾:血缘不是平台功能,是企业的"数据变更内控"。
- 立项前先量化痛点——变更事故、定位时长、审计响应
- 三期推进——MVP → 深化 → 控制闭环
- 用可量化指标验收——30 秒 / 5 分钟 / 1 小时
- 避开 9 个常见坑——不要只建图、要有 Owner、要进流程
数据血缘最有价值的一句话,不是"我们也有血缘平台了"。
而是:
当血缘能承载这四件事,它就从"图"变成了"系统能力"。
相关信息
- 讲透数据血缘!建议收藏
- 人到40才懂:那点死工资,是我养伤半年悟透的体面。
- 银行绩效二次分配:那些被“合理切割”的工资,与沉默的大多数
- 遭人欺负别急着翻脸,“戳痛处”才是绝杀
- 为什么现在不少单位里趋炎附势成了一条捷径?
- 总觉得自己“反应迟钝”?这种关键敏感度,其实人人可训练
- 头条真的很适合我这个宅女
- 当我做了超级个体后,我发现这5种底层能力是必须要修炼的
- 灵活就业人员到底算不算失业群体?答案一文说清
- 写材料不用愁!领导超爱的“单押”词汇,让你的文稿瞬间提档次
- 鲜为人知!90年代职业“被取消”,是时代必然?
- 失业第一天
- 长沙人气茶饮品牌茶颜悦色将首进深圳?已有招聘信息
- 年轻人搞不定的问题,成了我50岁后最稳定的收入来源
- 胖东来之后,又一家企业在学"分钱哲学"
- 2014前机关事业退休人员:国发2号文定待遇 工龄和地方补这样算
- 办公室真活得通透的,不是交际花,不是老黄牛,是风暴中的局外人
- 安徽省工资支付规定
- 名为外包实为派遣,应当由谁支付赔偿金?
- 山西出台《市场化引才奖励办法》